
How I collected game data from every NFL game
Before I get into anything technical, I have to start off by saying that I am a huge NFL fan. During the months of September through February, my mind is constantly on the NFL. I’m a die-hard Eagles fan; I don’t think I’ve missed an Eagles game in 10 years, and I definitely don’t plan on missing one in the future. Combining two of my passions (Football and Coding) has opened my mind to different ways of thinking about both the game of football, and also my career in software development.
But before we can do anything interesting, we have to gather the data. The NFL doesn’t have an official source for it’s data and thus many paid alternatives have become the best way to get data. Sites like Armchair Analysis provide huge data sets with tons of great information. At the time of this posting, a lifetime subscription to their service is $50, and that includes updates for each season after the superbowl each year.
But I’m cheap. I wanted the data for free, and I also wanted to learn how to write a scraper to do so. So I did. My favorite site to get NFL data is Pro Football Reference. It contains all the stats you want plus some that you didn’t even knew existed. It’s free to view and easy to find the information that you need. There’s only one problem, it doesn’t have an API. Not a problem, let’s get started!
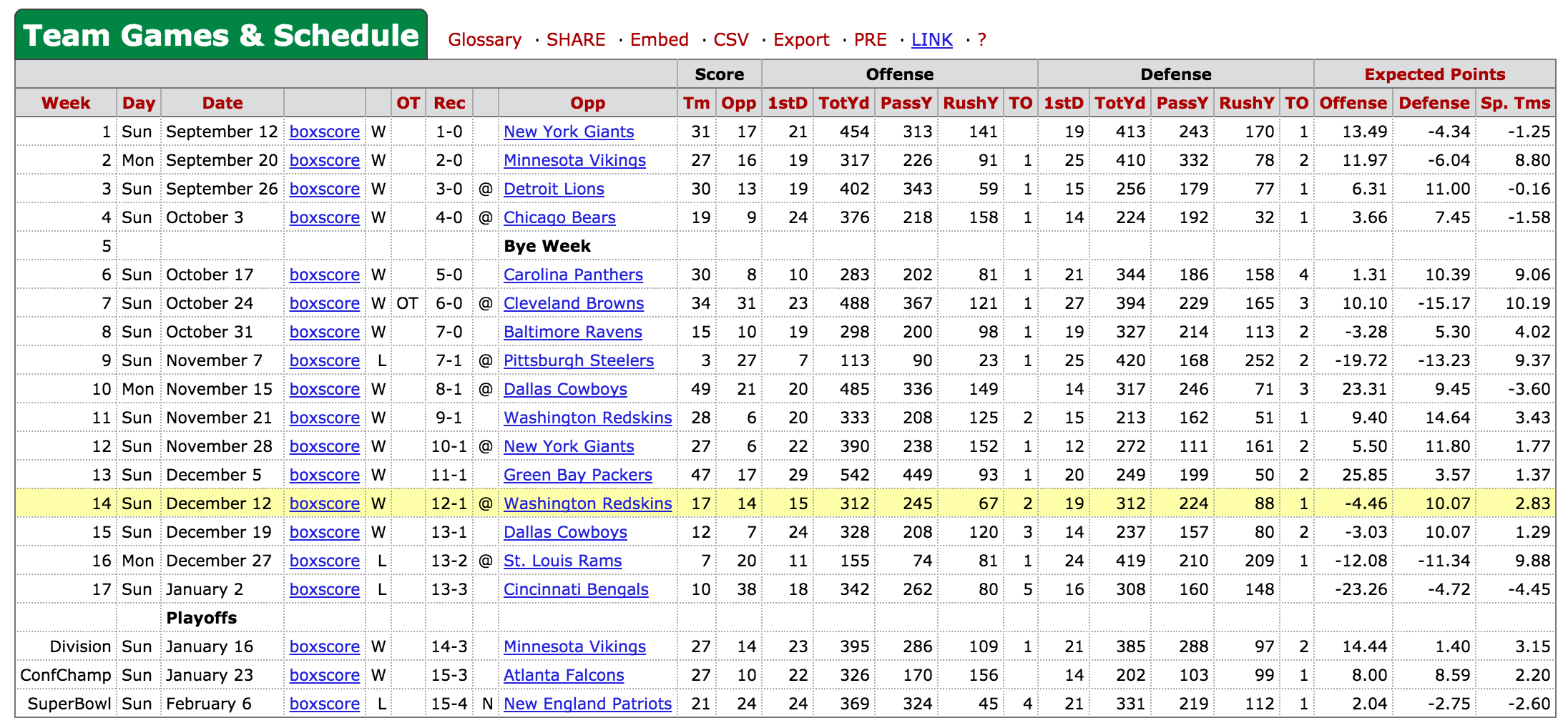
First let’s take a look at the season page for the 2004 Eagles, they were pretty good that year, and even made it to the superbowl. The data that we’re interested in today is the season summary i.e. a summary of every game that season.
You’ll need Requests to make the HTTP GET request for the data, and Beautiful Soup to parse the data.
pip install requests
pip install beautifulsoup4
Let’s take the URL for the Eagles that season, and grab it’s HTML. If we get a good request, we’ll create a BeautifulSoup object to parse it.
season_url = 'http://www.pro-football-reference.com/teams/phi/2004.htm'
res = requests.get(season_url)
# PFR will redirect you to a 404 page if not found
# but still serves you a 200 response
if '404' in res.url:
raise Exception('No data found for team %s in year %s' % (team, year))
soup = BeautifulSoup(res.text)With this soup object we can now start parsing the data. Let’s take a look at the HTML in Chrome. If you hover over the code in the inspector, it will show you what part of the page it corresponds to. In this case, we want to find the div element that has the class table_container, and the id div_team_gamelogs. After we find that div, we want all of the td elements inside of it. Pro Football Reference uses the same class (table_container) to hold all of it’s tables for future reference.
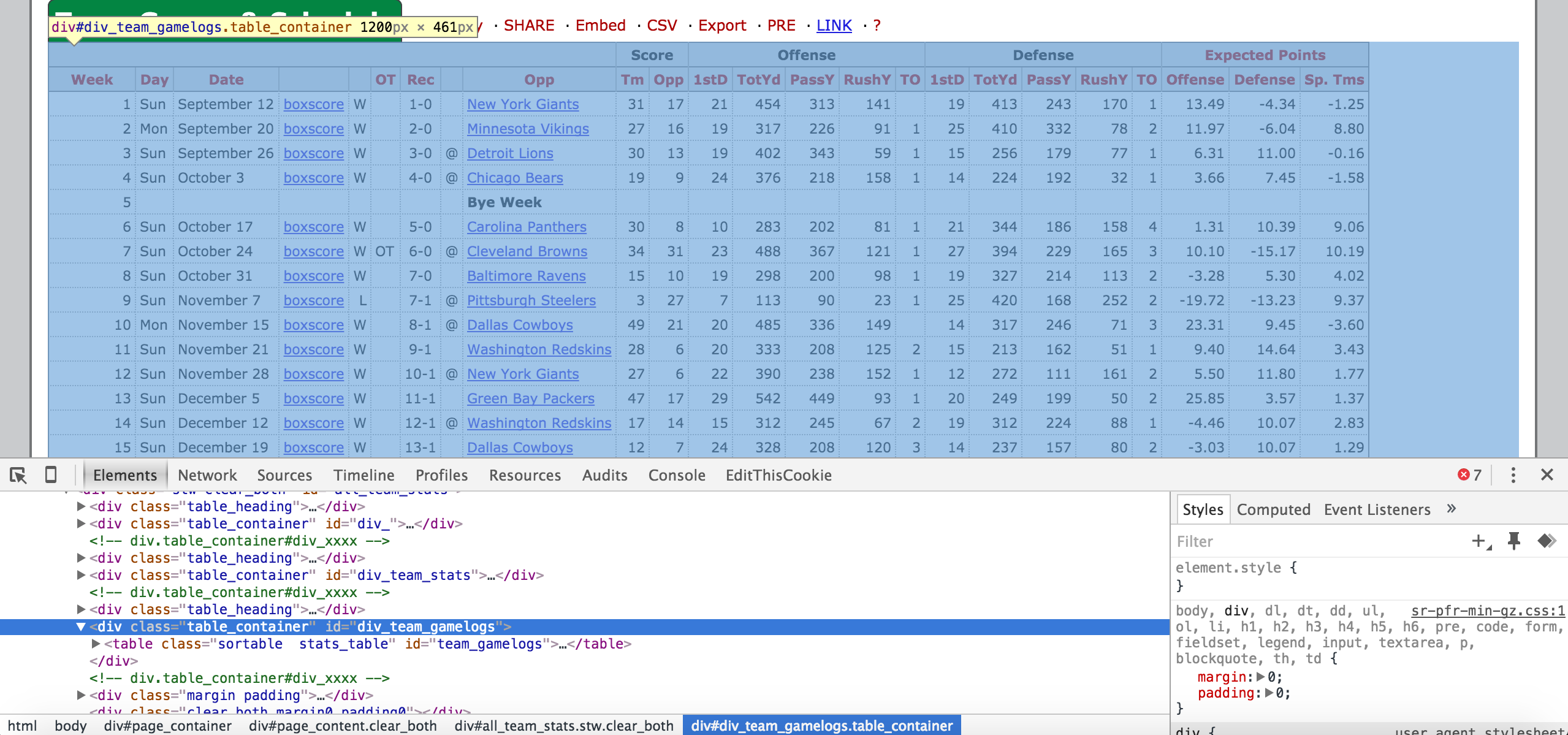
parsed = soup.findAll(
'div', {
'class': 'table_container',
'id': 'div_team_gamelogs'
}
)
rows = parsed[0].findAll('td')We should have a flat list of all of the data in this table. Let’s break it into rows so we have data on each individual game.
# After 1994, they added 3 more columns
column_len = 24 if int(year) >= 1994 else 21
# Group the rows into the number of columns
grouped_rows = [
rows[i:i+column_len] for i in range(0, len(rows), column_len)
]Now we have a list of lists, each inner list corresponding to a week in the season. The td elements are still in their original form and thus have html tags surrounding them. Let’s strip off the HTML tags to get cleaner looking data.
def _strip_html(text):
tag_re = re.compile(r'<[^>]+>')
return tag_re.sub('', str(text))Apply that to our rows…
[map(lambda x: _strip_html(x), row) for row in grouped_rows]Beautiful. Now we have something that looks like this…
[['1', 'Sun', 'September 12', 'boxscore', 'W', '', '1-0', '', 'New York Giants', '31', '17', '21', '454', '313', '141', '', '19', '413', '243', '170', '1', '13.49', '-4.34', '-1.25']
['2', 'Mon', 'September 20', 'boxscore', 'W', '', '2-0', '', 'Minnesota Vikings', '27', '16', '19', '317', '226', '91', '1', '25', '410', '332', '78', '2', '11.97', '-6.04', '8.80']
['3', 'Sun', 'September 26', 'boxscore', 'W', '', '3-0', '@', 'Detroit Lions', '30', '13', '19', '402', '343', '59', '1', '15', '256', '179', '77', '1', '6.31', '11.00', '-0.16']...]To grab data from any other team for any other year, we just need to edit the URL. A simple string formatting will do…
season_url = 'http://www.pro-football-reference.com/teams/%s/%s.htm' % (team, year)You can request any year (although some might not exist), with any team. Here is a list of all of the three letter codes for active franchises in the NFL
FRANCHISES = ['crd', 'atl', 'rav', 'buf', 'car', 'chi', 'cin', 'cie', 'dal',
'den', 'det', 'gnb', 'htx', 'clt', 'jax', 'kan', 'mia', 'min',
'nwe', 'nor', 'nyg', 'nyj', 'rai', 'phi', 'pit', 'sdg', 'sfo',
'sea', 'ram', 'tam', 'oti', 'was']My code can be found here. Just call the build_team_file() method in build_data_set.py with the team of your choice and out comes a csv of the data.